
The financial ecosystem has seen a tremendous extension since its formal inception in the year 1770 with the establishment of the Bank of Hindustan. Mere services grew to a full stack of financial services and with the digital revolution, services have been shifting online.
Digital banking forms are rapidly increasing across the globe. Payments companies are experiencing a swell in their transaction volume. In the financial year 2022, around 71 billion digital payments were recorded across India.
The evolution of financial services has also resulted in evolved financial fraud. These frauds are prevented by cybersecurity and cyber-crime teams who analyze and undertake several measures for a healthy financial ecosystem. Most financial institutions have dedicated teams of analysts who build and maintain automated systems to track transactions and red-flag potential fraudulent activities. Despite such efforts, fraudulent activities have been on an upward trend over the years.
Number of bank fraud cases across India – FY 2009 to 2022
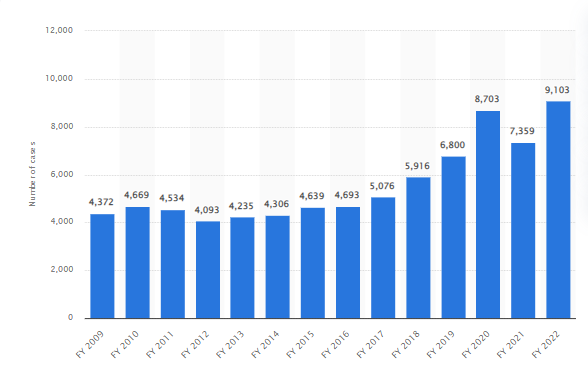
Source: Statista
As per data, reported frauds in FY 21-22 amounted to Rs 60,414 crore; a decrease of 56.28% from Rs 1.38 trillion in FY 20-21. Referring to the number of frauds, the data reported 23.69% higher frauds in FY 21-22 as compared to FY 20-21. Despite a lower value, the number of fraudulent cases has been the highest in FY 2022 at 9,103.
Value of bank frauds in India – FY 2018 to 2022, by category of fraud (in billion Indian rupees)
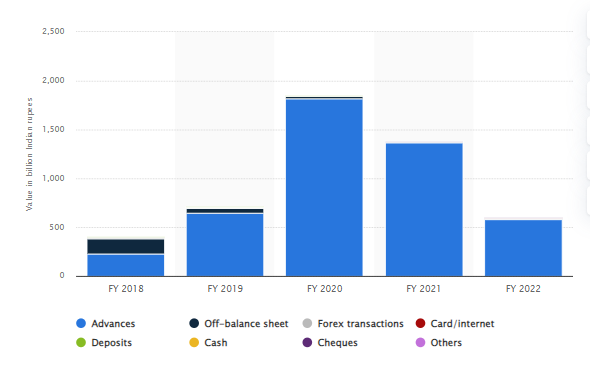
Source: Statista
As per the graph drawn from Statista, loan portfolios, both in terms of number and value, face the most fraud. Advances constituted 42.2% in number and a whopping 97% standing at Rs 58,328 crore in value. Cards/internet constituted 39.5% of the total frauds in number and 0.2% in value.
An analysis of the root cause of fraud shows a significant time lag between the date and time of occurrence and its detection. This comes as a challenge to financial institutions that are trying to mitigate fraud from their balance sheets. Therefore, financial institutions are automating the prevention and detection process with the help of Machine Learning.
The Machine Learning process to identify and thereby classify a case as fraud can be categorized into 2 major methods-
- Logistic regression
- Random Forest
To measure the performance of both models, Recall is a useful metric. High-class imbalance datasets typically result in poor Recall, although accuracy may be high. Precision will also be a consideration because reduced precision implies that the financial institution that is trying to detect fraud will incur more costs in screening the transactions. In fraud detection problems, though, accurately identifying fraudulent transactions is more critical than incorrectly classifying legitimate transactions as fraudulent.
Where financial institutions are investing heavily in fraud prevention, Machine Learning has allowed them to analyze and detect fraud effectively to a certain extent. However, they must ensure that the model and method they pick must give them an analysis that includes data cleaning, exploratory analysis and predictive modeling.